RabbitMQ 高级特性——消息可靠性
Science is gold.
平时在购物支付的时候,一般我们使用支付宝或微信转账支付的时候,都是扫码、支付,然后立刻得到结果,说你支付了多少钱,如果你绑定的是银行卡,可能这个时候你并没有收到支付的确认消息。往往是在很短的一段时间之后,才会收到银行卡发来的短信,告诉你支付的信息。
支付平台如何保证这笔帐不出问题?
支付平台必须保证数据正确性,保证数据的并发安全性,保证消息最终一致性。
我们可以通过一下几种方式保证数据一致性:
分布式锁
操作某条数据时先对其进行锁定,可以使用
Redis或Zookeeper等实现。比如我们在对帐单发起支付时,先锁定该账单,如果此时有其他线程操作该账单,则会阻塞等待直到锁释放后获取到锁才能依次执行。
优点:可以保证数据强一致性。
缺点:高并发场景下有性能问题。
消息队列
使用消息队列是弱一致性,可以保证数据最终一致性。
为了保证最终一致性,需要确保消息队列有 ack 机制。客户端收到消息消费处理完成后,客户端发送 ack 消息给消息中间件,如果消息中间件超过指定时间还没收到 ack ,则定时重发消息。
比如用户在充值完成后,会发送充值消息给账户系统,账户系统再去更改用户余额。
优点:异步、高并发
缺点:有一定延时、数据弱一致性。
如何保证消息可靠性
消息从生产者发送到消费者接收并消费,会在哪些情况下有消息丢失呢?
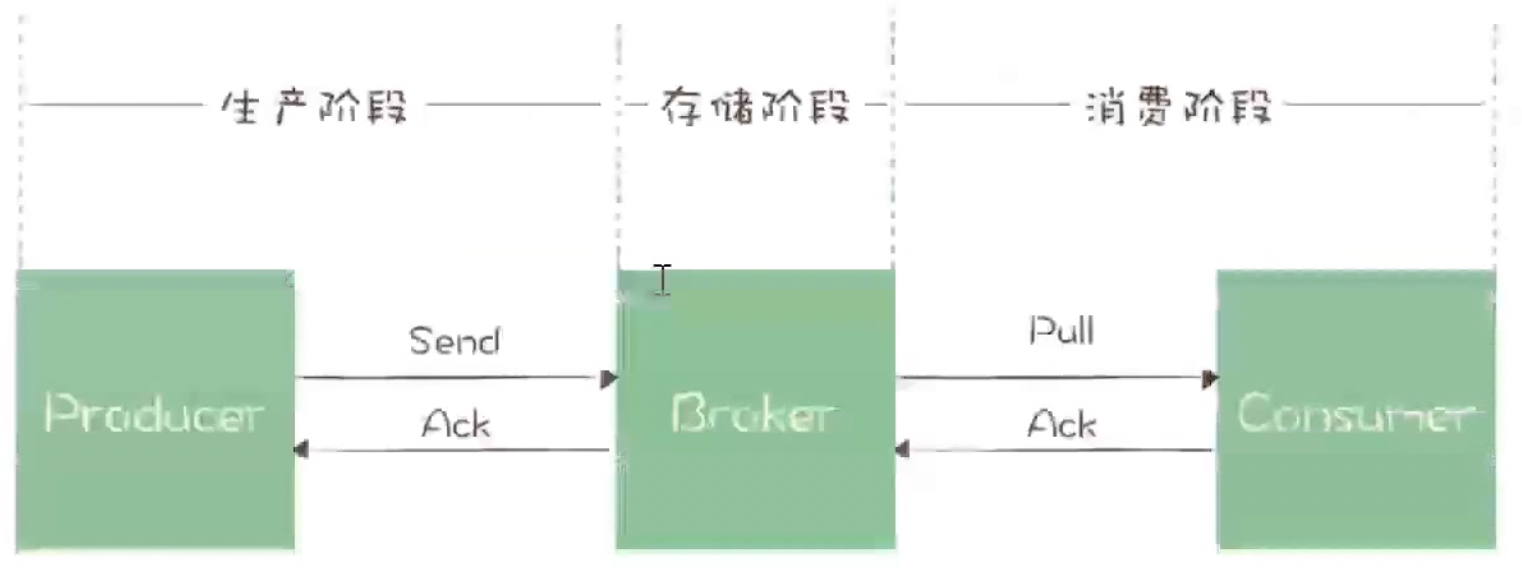
首先看一下消息发送的流程:生产者发送消息到 broker 的交换器,交换器能正确转发到队列,消费者从队列读取消息并消费。
要做到消息不丢失,我们必须要知道 broker 确实接收到了生产者发送的消息,保证broker内消息不丢失,消费者确实接收到消息并成功处理了。
我们可以从以下几个方面保证可靠性:
- 客户端代码中的异常捕获,包括生产者和消费者
- AMQP/RabbitMQ的事务机制
- 发送端确认机制
- 消息持久化机制
- Broker端的高可用集群
- 消费者确认机制
- 消费端限流
- 消息幂等性
1)异常捕获机制
先执行行业务操作,业务操作成功后执行行消息发送,消息发送过程通过 try catch 方式捕获异常,在异常处理理的代码块中执行回滚业务操作或者执行重发操作等。这是一种最大努力确保的方式,并无法保证100%绝对可靠,因为这里没有异常并不代表消息就一定投递成功。
bool result = DoBiz();
if(result)
{
try
{
SendMsg();
}
catch(Exception ex)
{
// RetrySend();
// DelaySend();
RollbackBiz();
}
}
2)AMQP/RabbitMQ的事务机制
没有捕获到异常并不能代表消息就一定投递成功了。 一直到事务提交后都没有异常,确实就说明消息是投递成功了。但是,这种方式在性能方面的开销比较大,一般也不推荐使用。
try
{
// 将 channel 设置为事务模式
channel.TxSelect();
// 发布消息到交换器,
channel.BasicPublish(exchangeName,"",null,message);
// 提交事务,只有消息成功被 Broker 接收了才能提交
channel.TxCommit();
}
catch(Exception ex)
{
// 事务回滚
channel.TxRollback();
}
3)发送端确认机制(Publisher Confirms)
RabbitMQ 后来引入了一种轻量级的方式,叫发送方确认(Publisher COnfirms)机制。生产者将 channel 设置成 confirm (确认)模式,一旦信道进入 confirm 模式,所有在该信道上面面发布的消息都会被指派一个唯一的 ID (从1开始),一旦消息被投递到所有匹配的队列之后(如果消息和队列是持久化的,那么确认消息会在消息持久化后发出) ,RabbitMQ 就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一 ID), 这样生产者就知道消息已经正确送达了。
RabbitMQ 回传给生产者的确认消息中的 DeliveryTag 字段包含了确认消息的序号,另外,通过设置 channel.BasicAck 方法中的 multiple 参数,表示到这个序号之前的
所有消息是否都已经得到了处理了。生产者投递消息后并不需要一直阻塞着,可以继续投递下一条消息并通过回调方式处理理 ACK 响应。如果RabbitMQ因为自身内部错误导致消
息丢失等异常情况发生,就会响应一条 nack(Basic.Nack) 命令, 生产者应用程序同样可以在回调方法中处理该 nack 指令。
具体详见 Publish Confirms(发布者确认模式)
4)消息持久化机制
持久化是提高 RabbitMQ 可靠性的基础,否则当 RabbitMQ 遇到异常时(如:重启、断电、停机等)数据将会丢失。主要从以下几个方面来保障消息的持久性:
Exchange的持久化。通过定义时设置durable参数为ture来保证Exchange相关的元数据不不丢失。_channel.ExchangeDeclare(_exchangeName,ExchangeType.Topic,true);Queue的持久化。也是通过定义时设置durable参数为ture来保证Queue相关的元数据不不丢失。_channel.QueueDeclare(QueueName, true, false, true);消息的持久化。通过将消息的投递模式(BasicProperties中的deliveryMode属性)设置为2即可实现消息的持久化,保证消息自身不丢失。var basicProperties = _channel.CreateBasicProperties(); basicProperties.DeliveryMode = 2; // basicProperties.Persistent = true; // 或者将 Persistent 设置为 true ,true 代表 DeliveryMode = 2 , false 代表 DeliveryMode = 1; _channel.BasicPublish(_exchangeName, routeKey, basicProperties, body);
RabbitMQ中的持久化消息都需要写入磁盘(当系统内存不不足时,非持久化的消息也会被刷盘处理理), 这些处理理动作都是在"持久层"中完成的。 持久层是一个逻辑上的概念,实际包含两个部分:
队索索引(rabbit_queue_index),rabbit_queue_index负责维护 Queue 中消息的息,包括消息的存储位置、是否已交给消费者、是否已被消费及Ack确认等,每个 Queue 都有与之对应的rabbit_queue_index。消息存储(rabbit_msg_store),rabbit_msg_store以键值对的形式存储消息,它被所有队列列共享,在每个节点中有且只有1个。
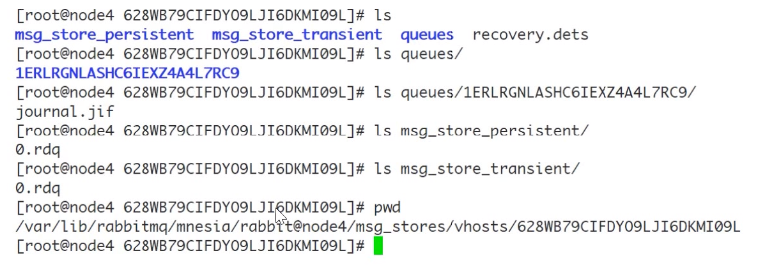
下图中,$RABBITMQ_HOME/var/lib/mnesia/rabbit@$HOSTNAME/msg_stores/vhosts/$VHostld 这个路径下包含 queues、msg_store_persistent、msg_store_transient 这3个目录,这是实际存储消息的位置。
queues目录中保存着rabbit_queue_index相关的数据,而msg_ store_persistent保存着持久化消息数据,msg_store_transient保存着非持久化相关的数据。 另外,RabbitMQ 通过配置queue_index_embed_msgs_below可以根据消息大小决定存储位置,默认queue_index_embed_msgs_below是4096 字节(包含消息体、属 性及 headers), 小于该值的消息存在rabbit_queue_index中。
5)消费者确认(Consumer ACK)
如何保证消息被消费者成功消费?
前面我们讲了 Publisher Confirms 和消息的持久化存储机制,然而这依然无法完全保证整个过程的可靠性,因为如果消息被消费过程中业务处理失败了但是消息却已经出列了 (被标记为已消费了), 我们又没有任何重试,那结果跟消息丢失没什么分别。
RabbitMQ 在消费端会有 Ack 机制,即消费端消费消息后需要发送 Ack 确认报文给 Broker 端,告知自己是否已消费完成,否则可能会一直重发消息直到消息过期(AUTO 模式)。
这也是我们之前一直在讲的“最终一致性"、 “可恢复性”的基础。
一般来说,我们有如下处理手段:
- 采用
NONE模式,消费的过程中自行捕获异常,引发异常后直接记录日志并落到异常恢复表,再通过后台定时任务扫描异常恢复表尝试做重试动作。如果业务不自行处理则有丢失数据的风险 - 采用
AUTO (自动 Ack)模式,不主动捕获异常,当消费过程中出现异常时会将消息放回 Queue 中,然后消息会被重新分配到其他消费者节点(如果没有则还是选择当前节点) 重新被消费,默认会一直重发消息并直到消费完成返回 Ack 或者一直到过期 采用
MANUAL (手动 Ack)模式,消费者自行控制流程并手动调用channel相关的方法返回 Ackvar consumer = new EventingBasicConsumer(_channel); consumer.Received += (model, ea) => { string message = Encoding.UTF8.GetString(ea.Body.ToArray()); Console.WriteLine($"Queue:{QueueName} \t Exchange: {ExchangeName} \t RoutingKey: {ea.RoutingKey} \t BindingKey:{RouteKey} \t Message: {message}"); // 手动 ack, DeliveryTag 表示消息的唯一标志, multiple 表示是否为批量确认 _channel.BasicAck(ea.DeliveryTag,false); // 手动 nack, 告诉 broker 消费者处理失败,最后一个参数表示是否需要将消息重新入队列 _channel.BasicNack(ea.DeliveryTag,false,true); // 手动拒绝消息。第二个参数表示是否需要将消息重新入队列 _channel.BasicReject(ea.DeliveryTag,true); }; _channel.BasicConsume(QueueName, false, consumer);
6)消费端限流
在电商的秒杀活动中,活动一开始会有大量并发写请求到达服务端,需要对消息进行削峰处理, 如何削峰? 当消息投递速度远快于消费速度时,随着时间积累就会出现"消息积压”。消息中间件本身是具备一定的缓冲能力的,但这个能力是有容量限制的,如果长期运行并没有任何处理,最终会导致Broker崩溃,而分布式系统的故障往往会发生上下游传递,连锁反应那就会很悲剧...
下面从多个角度介绍 QoS 与限流,防止上面的悲剧发生。
RabbitMQ 可以对内存和磁盘使用量设置阈值,当达到阈值后,生产者将被阻塞(block),直到对应项指标恢复正常。全局上可以防止超大流量、消息积压等导致的 Broker 被压垮。当内存受限或磁盘可用空间受限的时候,服务器都会暂时阻止连接,服务器将暂停从发布消息的已连接客户端的套接字读取数据。连接心跳监视也将被禁用。所有网络连接将在
rabbitmqctl和管理插件中显示为“已阻止”,这意味着它们尚未尝试发布,因此可以继续或被阻止,这意味着它们已发布,现在已暂停。兼容的客户端被阻止时将收到通知。在
/etc/rabbitmq/rabbitmq.conf中配置磁盘可用空间大小:# 设置磁盘可用空间大小,单位字节。当磁盘可用空间低于这个值的时候, # 发出磁盘警告,触发限流。 # 如果设置了相对大小,则忽略此绝对大小 disk_free_limit_absolute = 50000 # 使用计量单位,从RabbitMQ 3.6. 0开始有效。对vm_menory_high_waternark同样有效 # disk_free_limit_absolute = 500KB # disk_free_limit_absolute = 50mb # disk_free_limit_absolute = 5GB ## Alternatively, we can set a limit relative to total available RAM. ## ## Values lower than 1.0 can be dangerous and should be used carefully. # 还可以使用相对于总可用内存的相对值来设置。注意:此相对值不要低于1.0! # 当磁盘可用空间低于总可用内存的2.0倍的时候,触发限流 # disk_ free_limit_relative = 2.0 # 内存限流阈值设置 # 0.4表示阈值和总可用内存的比值。总可用内存表示操作系统给每个进程分配的大小,或实际内存大小 # 如32位Windows,系统给每个进程最大2GB的内存,则此比值表示阈值为820MB # vm_memory_high_watermark.relative = 0.4 # # 还可以直接通过绝对值限制可用内存的大小。单位字节。 # vm_memory_high_watermarkk.absolute = 1073741824 # # 从RabbitMQ 3.6.0开始,绝对值支持计量单位。如果设置了相对值,则忽略此相对值。 # vm_memory_high_watermark.absolute = 2GB # #支持的单位: # # k, kiB: kibibytes (2^10 - 1,024 bytes) # M, MiB: mebibytes (2^20 - 1,048,576 bytes) # G, GiB: gibibytes (2^30 - 1,073,741,824 bytes) # kB: kilobytes (10^3 - 1,000 bytes) # MB: negabytes (10^6 - 1 , 000,000 bytes) # GB: gigabytes (10^9 - 1, 000 , 000 , 000 bytes)RabbitMQM 还默认提供了一种基于 credit flow 的流控机制,面向每个连接进行流控。当单个队列达到最大流速时,或者多个队列达到总流速时,都会触发流控。触发单个连接的流控可能是因为 connection、channel、queue 的某一个过程处于 flow 状态,这些状态都可以从监控平台上看到。

RabbitMQ 中有一种
QoS保证机制,可以限制 Channel 上接收到的未被 Ack 的消息数量,如果超过这个数量限制 RabbitMQ 将不会再往消费端推送消息。这是一种流控手段,可以防止大量消息瞬时从 Broker 送达消费端造成消费端巨大压力(甚至压垮消费端)。比较值得注意的是 QoS 机制仅对于消费端推模式有效,对拉模式无效。而且不支持NONE Ack模式。执行channel.BasicConsume方法之前通过channel.BasicQos方法可以设置该数量。// 消费者设置 Qos,告诉 Rabbit 每次只能向消费者发送 1 条消息,消费者未确认之前,不再向他发送信息 _channel.BasicQos(prefetchSize:0, prefetchCount:1, global:false); var consumer = new EventingBasicConsumer(_channel); consumer.Received += (model, ea) => { ... // 接收消息处理 _channel.BasicAck(ea.DeliveryTag,false); } _channel.BasicConsume(QueueName,autoAck:false,consumer);消息的发送是异步的,消息的确认也是异步的。在消费者消费慢的时候,可以设置
Qos的prefetchCount,它表示 broker 在向消费者发送消息的时候,一旦发送prefetchCount个消息而没有一个消息确认的时候,就停止发送。消费者确认一个, broker 就发送一个,确认两个就发送两个。 换句话说,消费者确认多少,broker 就发送多少,消费者等待处理的个数永远限制在prefetchCount个。 如果对于每个消息都发送确认,增加了网络流量,此时可以批量确认消息。如果设置了multiple为true,消费者在确认的时候,比如说 id 是 8 的消息确认了,则在 8 之前的所有消息都确认了。
生产者往往是希望自己产生的消息能快速投递出去,而当消息投递太快且超过了下游的消费速度时就容易出现消息积压/堆积,所以,从上游来讲我们应该在生产端应用程序中也可以加入限流、应急开关等控制手段,避免超过 Broker 端的极限承载能力或者压垮下游消费者。
再看看下游,我们期望下游消费端能尽快消费完消息,而且还要防止瞬时大量消息压垮消费端(推模式),我们期望消费端处理速度是最快、最稳定而且还相对均匀(比较理想化) 提升下游应用的吞吐量和缩短消费过程的耗时,优化主要以下几种方式:
- 优化应用程序的性能,缩短响应时间(需要时间)
- 增加消费者节点实例(成本增加,而且底层数据库操作这些也可能是瓶颈)
- 调整并发消费的线程数(线程数并非越大越好,需要大量压测调优至合理值)
可靠性保障
- Producer 需要开启事务机制或
publisher confirms,以确保消息可以可靠地传输到 RabbitMQ 中。 - Producer 需要配合使用
madatory参数或备份交换器来确保消息能够从交换器路由到队列中,进而能够保存下来而不会被丢弃。`mandatory`:设置为 `true` 时,如果 `exchange` 根据自身类型和消息 `routeKey` 无法找到一个符合条件的 `queue`,会调用 `basic.return` 方法将消息返还给生产者;设为 `false` 时,出现上述情形 broker 会直接将消息扔掉。 - 消息和队列都需要进行持久化处理,以确保 RabbitMQ 服务器在遇到异常情况时不会造成消息丢失。
- 消费者在消费消息时需要将
autoAck设为false,通过手动确认的方式确认已经正确消费消息,避免在消费端引起不必要的消息丢失。